Article
Algorithms and inequality: Can machines be prejudiced?


We must be more careful in selecting the people who design and train automated learning systems because artificial intelligence will reflect the values of its creators.
When we browse through our favorite social media sites, decide what to watch on Netflix or do a Google search for something, we are allowing ourselves to be guided by an algorithm, a set of rules that determine, among other potential parameters, what content could interest us the most and what information best fits our lifestyle and preferences.
In order for the results to match our interests as much as possible, algorithms are fed enormous amounts of information from which they establish relationship nodes and find patterns. Frequently, the data used to feed an algorithm is selected by humans beforehand. The problem lies in the fact that sometimes the decision on what information should be included or excluded can be biased in terms of race or gender. “Algorithms are automated and simplified versions of the bureaucratic human process they have replaced. They are trained using the historical data produced by the original process,” explains Cathy O’Neill, a mathematician and author of Weapons of Math Destruction (Capitán Swing 2016), “which this means that if the process was systematically biased towards a certain group, then the same will usually apply to the resulting algorithm.”
“This is fundamentally a data issue. Algorithms learn by being fed certain images that are often selected by engineers, and the system builds a model of the world based on those images. A system that has been trained primarily using photos of white people will struggle to recognize non-white faces,” explains Kate Crawford, who specializes in the social implications of artificial intelligence. This statement can be confirmed with a simple exercise: ask a search engine to display “baby” images and most of the results will be white or Western babies.
A professor at University of Virginia detected a pattern in certain conjectures made by the image recognition software he was creating because “when he saw a photo of a kitchen, it was frequently associated with women as opposed to men.” Based on this observation, he wondered whether he had been feeding biased information to the algorithm, so he analyzed the image tags and realized that the photo banks he worked with showed a clear discrimination in how certain activities were represented. Images of shopping or cleaning were linked to women while actions such as exercising or shooting were tied to men. The problem worsened when the team realized that the automated learning program they had trained not only reflected those biases, but that it amplified them, thereby reinforcing the associations.
However, biases in machine learning and in the results displayed to users occur in more than just images. According to a Princeton University study, when artificial intelligence assimilates a new language, it also learns the discrimination that is present in that language, which means that it ultimately absorbs (and copies) certain stereotypes. The work of Aylin Caliskan, study’s first author, is based on the idea that certain characteristics in the meaning of words can be due to how they are arranged within the context. The researchers developed a software that was fed two million words to see how it made associations. The results were similar to those of the University of Virginia: the machine linked women’s names with household tasks and men’s names with words related to professional careers.
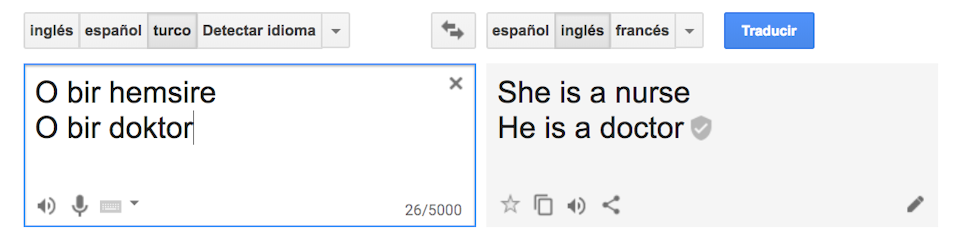
One of the cases analyzed by the study was machine translation, in which Turkish text was converted into English using the Google translation service. Despite the fact that Turkish has genderless pronouns, the translator interpreted the sentences to have stereotyped pronouns:


Other well-known examples of algorithms that displayed biased results were the Microsoft chatbot, a beauty pageant judged by artificial intelligence, and discrimination in Google employment ads. In the first example, the technology company created a Twitter account that was managed by AI software called Tay, which was designed to learn through its interactions with users. Although the experiment started off well, Tay quickly began to tweet racist and completely inappropriate messages. Microsoft closed the account and apologized for the results.
The first beauty pageant judged by artificial intelligence was held in 2016. The program was designed to judge impartial aspects such as facial symmetry and wrinkles, but out of the 44 winners, the majority were white, some were Asian and only one was a dark-skinned person. In view of the apparent objectiveness in the selection, the results reflected a clear preference towards light skin. According to the lead scientist, the main issue with the pageant was that the images used by the project to establish beauty standards did not include sufficient data for minorities.
Three years ago, Carnegie Mellon University revealed that high-paying job ads were shown to many more men than women. According to the study, an ad for a position paying more than $200,000 was displayed 1,800 times to male users as opposed to 300 times to female users. One of the potential effects of this type of gender-based discrimination is workplace inequality: women cannot apply to jobs that are not offered to them.
An algorithm is only as good as the data we input. “Artificial intelligence systems do not have intentionality but the decisions they learn are based on the data that is fed to them,” states the director of the AI Research Institute at the Spanish National Research Council. Although the examples used in this article are important, certain decisions made by artificial intelligence could have much more serious consequences: some algorithms decide who has the right to receive a mortgage, a life insurance policy or a college loan.
What can be done to make sure that algorithms do not perpetuate human biases? Inclusiveness is one of the solutions that many researchers believe in: we must be more careful in selecting the people who design and train automated learning systems because artificial intelligence will reflect the values of its creators. Building teams that include women and ethnic minorities could be a step towards reducing discrimination. Some specialists recommend for everyone involved in this type of technology to have some type of values training to help them understand the importance of their actions. Finally, other experts point out that the responsibility also lies in everyone who posts content on the Internet because machines learn from user interactions and data. Caliskan supports this concept and believes that if a more inclusive language was used, stereotypical associations would decrease.
Algorithms will be whatever we want them to be, so we cannot allow those machines, to which we give a certain degree of objectiveness and that make decisions for us and accompany us in our everyday lives, to copy and amplify human errors.

