Artículo
Algoritmos y desigualdad, ¿pueden las máquinas tener prejuicios?


Hay que ser más cuidadoso con quien se elige para diseñar y entrenar los sistemas de aprendizaje automático, pues la inteligencia artificial reflejará los valores de sus creadores.
Cuando navegamos por nuestras redes sociales favoritas, cuando estamos decidiendo qué ver en Netflix un domingo por la tarde o cuando buscamos cualquier cosa en Google, nos estamos dejando guiar por un algoritmo, un conjunto de reglas que determina, entre otros posibles parámetros, qué contenido nos puede interesar más y qué información se adecua con más precisión a nuestro estilo de vida y a nuestros gustos.
Para que los resultados que se nos muestren concuerden al máximo con nuestros intereses, a los algoritmos se les nutre con enormes cantidades de información, a partir de las cuales establecen nodos de relación y encuentran patrones. Frecuentemente, los datos con los que se ha alimentado al algoritmo son seleccionados previamente por humanos. El problema radica en que a veces la elección de qué información incorporar y qué datos obviar puede ser tendenciosa en cuanto a raza o género. “Los algoritmos son versiones automatizadas y simplificadas de cualquier proceso humano burocrático que hayan reemplazado. Están entrenados en los datos históricos que produjo ese proceso”, explica Cathy O’Neill, matemática y autora de Armas de destrucción matemática (Capitán Swing, 2016), “eso significa que, si el proceso estaba sesgado sistemáticamente a favor de cierto grupo, el algoritmo resultante normalmente también lo estará”.
“Esto es fundamentalmente un problema de datos. Los algoritmos aprenden siendo alimentados con ciertas imágenes, a menudo elegidas por ingenieros, y el sistema construye un modelo del mundo basado en esas imágenes. A un sistema entrenado con fotografías de personas que son, en su mayoría, blancas, le será más difícil reconocer caras no-blancas”, expone Kate Crawford, especialista en las implicaciones sociales de la inteligencia artificial. Esta afirmación se puede comprobar con un ejemplo sencillo: solicitemos a cualquier buscador imágenes de “bebé” o “baby” y tendremos infinitos resultados, mayoritariamente de bebés blancos y occidentales.
Un profesor de la Universidad de Virginia observó un patrón en algunas conjeturas hechas por el software de reconocimiento de imágenes que estaba creando, “veía una fotografía de una cocina y con frecuencia la asociaba con mujeres más que con hombres”. A partir de esta advertencia, se preguntó si había estado nutriendo el algoritmo con información sesgada, por lo que analizó los etiquetados de las imágenes que había usado: efectivamente, los bancos de fotografías con los que trabajaba mostraban una discriminación predecible en la representación que hacían de ciertas actividades. Mientras que imágenes de compras o de limpieza estaban relacionadas con mujeres, acciones como entrenar o disparar estaban vinculadas con hombres. El problema se agravó cuando el equipo se dio cuenta que el programa de aprendizaje automático que había entrenado no solo reflejaba estos sesgos, sino que los amplificaba, fortaleciendo estas asociaciones.
El sesgo en el aprendizaje de los softwares y, en consecuencia, en los resultados que se muestran a los usuarios, no ocurre solo con las imágenes. Cuando una inteligencia artificial asimila un idioma nuevo, aprende también la discriminación presente en el propio lenguaje, por lo que acaba apropiándose (y reproduciendo) algunos estereotipos, según un estudio de la Universidad de Princeton. El trabajo de Aylin Caliskan, autora principal de la investigación, parte de la idea de que algunas características del significado de las palabras pueden deberse a la forma en que éstas están ordenadas, al contexto sobre el que están dispuestas. Los investigadores desarrollaron un software nutrido con 2 millones de palabras, para ver cómo realizaba asociaciones. Los resultados fueron similares a los de la Universidad de Virginia: la máquina relacionaba nombres femeninos con tareas del hogar y nombres masculinos con palabras vinculadas a la carrera profesional.
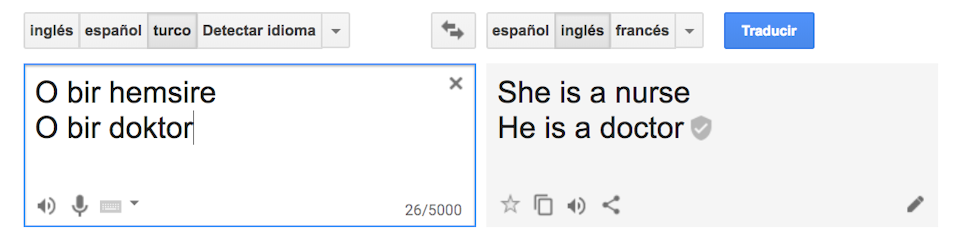
Un caso analizado dentro de este estudio fue la traducción automática, poniendo como ejemplo la traducción del turco al inglés con el servicio de traducción de Google. A pesar de que el turco tiene pronombres neutros, el traductor interpretó las frases con pronombres estereotipados:


Otros ejemplos sonados de algoritmos que mostraron resultados sesgados fueron el chatbot de Microsoft, el concurso de belleza con una inteligencia artificial como juez y la discriminación en los anuncios de empleo en Google. En el primer caso, la compañía tecnológica creó una cuenta de Twitter gestionada por un software de IA llamado Tay, que estaba diseñada para que fuera aprendiendo a través de las interacciones que los usuarios tuvieran con ella. A pesar de que el experimento empezó bien, Tay pasó rápidamente a divulgar mensajes racistas y completamente inapropiados. Microsoft cerró la cuenta y se disculpó por los resultados.
En 2016, tuvo lugar el primer concurso de belleza juzgado por inteligencia artificial. El programa prometía juzgar aspectos imparciales como la simetría del rostro o las arrugas, pero de los 44 ganadores, la mayoría eran blancos, algunos asiáticos y sólo una persona de piel oscura. Ante la aparente objetividad de la selección, los resultados reflejaban una clara preferencia hacia la piel clara. El problema principal, según el responsable científico del concurso, fue que las imágenes que el proyecto usó para establecer los estándares de belleza no incluían suficientes datos de minorías.
La Universidad Carnegie Mellon reveló hace tres años que se mostraban anuncios de empleo de retribución elevada a bastantes más hombres que a mujeres. Según el estudio que se llevó a cabo, el anuncio de un puesto de trabajo con un sueldo de más de 200.000 dólares se mostró 1.800 veces a usuarios masculinos, mientras que sólo se enseñó 300 veces a usuarios femeninos. Uno de los posibles efectos de este tipo de discriminación basada en el género es la desigualdad en los puestos de trabajo: las mujeres no pueden aplicar a puestos de trabajo que no se les ofrecen.
Todos los algoritmos son tan buenos como los datos que pongamos en ellos. “Ningún sistema de inteligencia artificial tiene intencionalidad, pero las decisiones que aprende están basadas en los datos con los cuales ha sido entrenado”, afirma el director del Instituto de Investigación en IA del CSIC. Aunque los ejemplos que se han utilizado en este artículo son importantes, hay decisiones que toman inteligencias artificiales que pueden tener consecuencias aún más graves: hay algoritmos que deciden quién tiene derecho a una hipoteca, a un seguro de vida o a un préstamo universitario.
¿Qué se puede hacer para conseguir que los algoritmos no perpetúen los sesgos humanos? La inclusividad es uno de los ejes por los que muchos investigadores apuestan: hay que ser más cuidadoso con quien se elige para diseñar y entrenar a los sistemas de aprendizaje automático, pues la inteligencia artificial reflejará los valores de sus creadores. Formar equipos donde se incluyan mujeres y minorías étnicas podría ser uno de los pasos hacia una menor discriminación. Algunos especialistas aconsejan, además, que todos los involucrados en este tipo de tecnologías tengan algún tipo de formación en valores, para que sean conscientes de la importancia de sus acciones. Finalmente, otros expertos señalan que la responsabilidad es también de todos los que volcamos contenidos en la red, pues las máquinas aprenden de los datos y de las interacciones de los usuarios. En esta línea coincide Caliskan, que afirma que, si se utilizara un lenguaje más inclusivo, las asociaciones estereotípicas disminuirían.
Los algoritmos serán como nosotros queremos que sean y no nos podemos permitir que aquellas máquinas que toman decisiones por nosotros, que nos acompañan en el día a día y a las que otorgamos un cierto grado de objetividad reproduzcan y amplifiquen los errores humanos.

