Article
Quatre claus per evitar els prejudicis en la IA


La IA no és ni bona ni dolenta, dependrà de com l’entrenem
Recentment va sortir la notícia que la intel·ligència artificial d’Amazon, tecnologia que va utilitzar des de l’any 2014 fins a principis de 2017 per seleccionar currículums, discriminava a les dones. Aquesta no és la primera vegada que s’informa d’aquest tipus de problema, i no serà l’última, ja que els sistemes esbiaixats són un parany en el qual les empreses poden caure fàcilment.
En el cas del gegant del comerç electrònic, que ha deixat d’utilitzar aquesta tecnologia en els seus processos de selecció de personal, el problema va radicar en què la IA havia estat entrenada amb currículums de fa 10 anys, amb una forta presència masculina. D’aquesta manera, la IA tenia un biaix en favor dels homes i penalitzava els currículums de dones, encara que la variable ‘sexe’ s’eliminés del model.
El problema va ser que ser dona o home estava molt correlacionat amb informació addicional implícita en els currículums (escola, aficions, el mateix nom, etc.). Per eliminar el biaix no n’hi havia prou suprimint la paraula ‘dona/home’, sinó que era necessari descobrir i eliminar tota la informació relacionada.
Què és un biaix?
No existeix una definició generalment acceptada de biaix, tret que és el contrari de justícia. Un vídeo tutorial publicat en YouTube a principis d’aquest any enumera 21 definicions diferents de justícia en un algoritme. Si bé no existeix una definició estàndard, hi ha un parell de pensaments clau sobre aquest tema:
Discriminació injusta i il·legal: Tractar a les persones de manera diferent
Hi ha molts tipus de discriminació il·legal, sent les més conegudes el gènere i la raça. No obstant això, hi ha científics de dades que construeixen models que utilitzen aquestes característiques per entrenar sistemes d’IA que posteriorment seran utilitzats per prendre decisions.
Una manera subtil que la discriminació s’introdueixi en un model és utilitzar característiques que estan fortament relacionades amb atributs discriminatoris. Per exemple, a Estats Units la raça d’una persona està estretament lligada amb el seu domicili. És per això que als bancs nord-americans no se’ls permet utilitzar codis postals al prendre decisions sobre préstecs.
És important tenir en consideració les característiques que no són ètiques, que podrien causar risc de reputació o aprofitar-se de col·lectius vulnerables. Per exemple, existeixen models econòmics que prediuen que els clients d’edat avançada tenen una sensibilitat de preus més baixa (tal vegada perquè no tenen la capacitat d’accedir a Internet per fer una comparativa de preus), per la qual cosa se’ls acaba cobrant imports considerablement més alts. En aquesta situació, no és il·legal cobrar-los més, però molts considerarien poc ètic aprofitar-se d’una persona vulnerable.
Consolidació del desavantatge històric
Una IA només sap el que se li ensenya. És com enviar a un nen a l’escola, aprèn amb l’exemple de les dades històriques. Si entrenes a un sistema d’IA amb dades esbiaixades, llavors aprendrà a prendre decisions esbiaixades. Els científics de dades, responsables de construir i formar aquests sistemes, tenen habilitats similars a les dels professors. De la mateixa manera que no utilitzem llibres de text de fa cent anys, no hauríem d’entrenar IAs amb dades que contenen resultats tendenciosos. Si les dades històriques contenen exemples de mals resultats per als grups desfavorits, llavors aquesta tecnologia aprendrà a reproduir les decisions que condueixen a aquests mals resultats.
Quan una IA aprèn a repetir els errors humans, mantindrà aquest comportament al futur. Per exemple, si un sistema d’IA es forma amb dades recopilades durant un període durant el qual les dones tenien menys probabilitats de tenir èxit al sol·licitar una ocupació (possiblement a causa de prejudicis o a rols tradicionals de gènere), llavors el sistema aprendrà a donar prioritat al col·lectiu masculí.
Cas d’estudi – Com evitar els prejudicis en els sistemes d’IA
Una empresa, anomenem-la Techcorp, vol construir un algoritme per classificar les grans quantitats de sol·licituds que rep cada vegada que publica un anunci de treball, per la qual cosa ha decidit entrenar un algoritme de machine learning amb els resultats de la seva campanya de contractació anterior (amb variables com l’edat, el gènere, l’educació i altres detalls sobre el perfil de cada sol·licitant).
Entrena l’algoritme a partir de les seves dades històriques i està molt satisfeta de poder predir quin candidat obtindrà el treball amb una taxa de precisió alta. Això hauria d’estalviar al seu equip de recursos humans la meitat del temps que passen llegint currículums.
Però aquest no és el final del projecte. Elle Smith, la nova Directora de Recursos Humans de Techcorp, no confia en la caixa negra. Es pregunta quins factors està utilitzant la IA per prendre les seves decisions. L’informe que rep de l’equip d’IA li mostra una representació de la importància que se li dóna a cada nova dada a l’hora de prendre decisions.


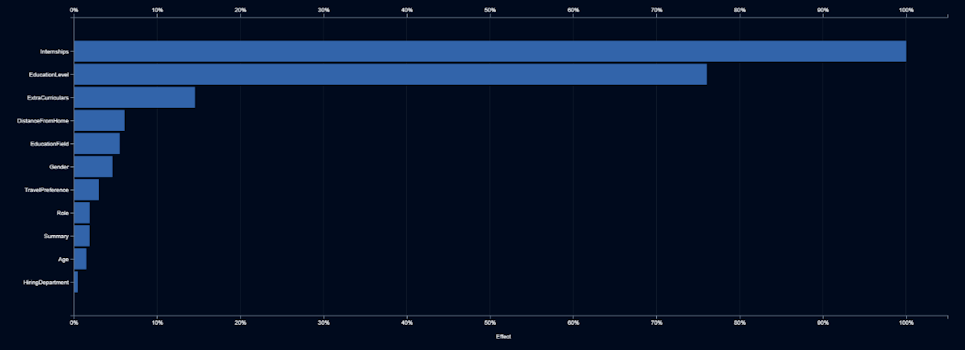
L’anterior informe li mostra que el gènere és el sisè input més important. Així que Elle Smith es pregunta què està succeint amb el gènere. La informació que rep li mostra el que fa la IA, amb diferents valors, per a una característica d’entrada:


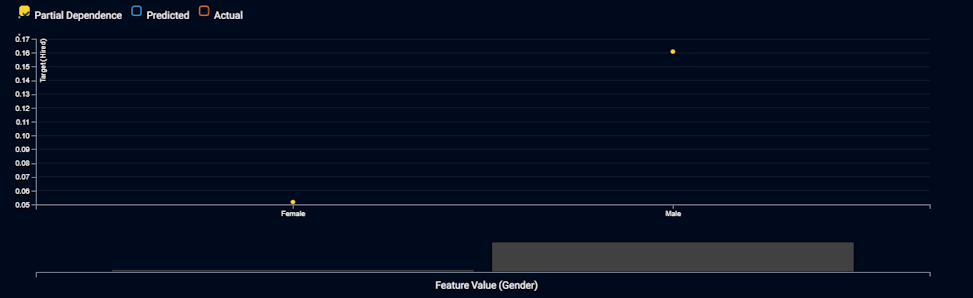
El gràfic mostra que la IA triarà 3 vegades més sovint als homes que a les dones, sent les altres variables igualitàries. Elle declara que això és discriminació directa i que és il·legal, i exigeix que l’equip d’IA elimini el gènere del model. Així que construeixen una nova IA que no utilitza el gènere com a variable.
L’equip d’IA presenta el seu model de segona generació i declara que és tan precís com el primer, malgrat haver abandonat el camp del gènere. Però Elle segueix sospitant, per la qual cosa demana consultar quines variables d’entrada són les més importants.

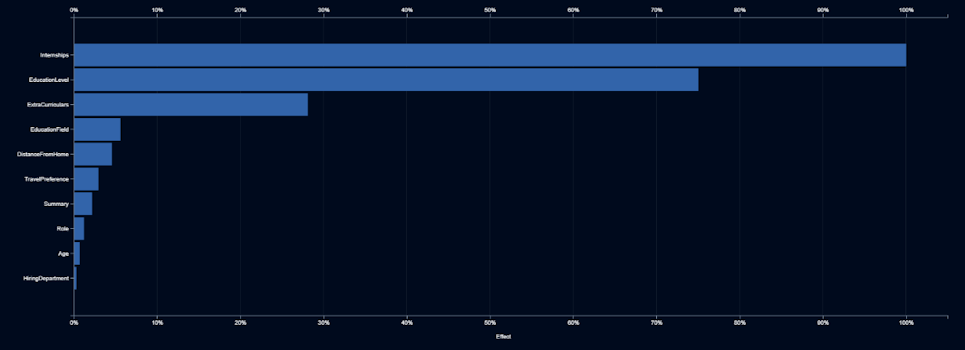
Elle detecta que els períodes de pràctiques, l’educació i les activitats extracurriculars són els indicadors més forts. Encara que tot això té sentit, una vegada més, es pregunta què està fent la IA amb aquestes característiques. Les beques i l’educació tenen sentit, ja que els més formats i amb més experiència tenen més probabilitats de ser contractats. Decideix buscar en un núvol de paraules la descripció d’activitats extracurriculars.



Descobreix que els candidats són més propensos a ser contractats si van practicar futbol, un esport dominat per homes; i menys propensos a ser contractats si van jugar a handbol o softbol, esports dominats per dones. A més, si el candidat forma part d’un equip esportiu femení de qualsevol mena, té encara menys probabilitats de ser contractat! El text que descriu les activitats extracurriculars resulta ser, en si, un indicador de gènere, així que utilitzar-ho no es diferencia gens a utilitzar el gènere.
Elle demana a l’equip d’IA que identifiqui qualsevol altra característica que pugui ser un indicador de gènere. Ho fan construint models que prediuen la probabilitat que un candidat sigui una dona, basant-se en qualsevol de les altres característiques.

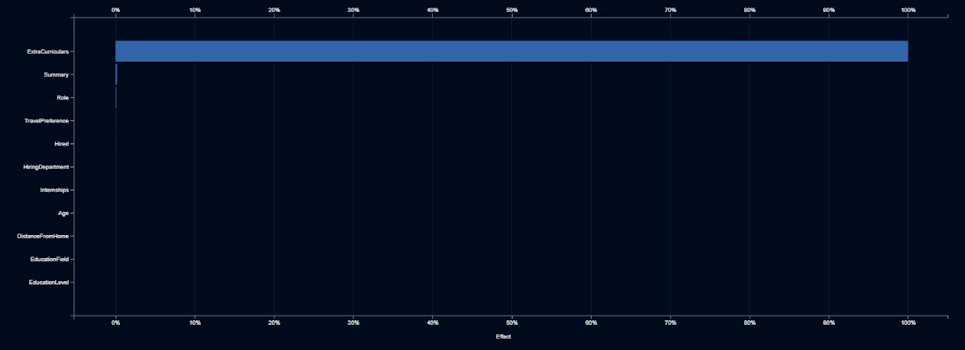
El gràfic mostra que l’activitat extracurricular és l’únic indicador significatiu de gènere, per la qual cosa Elle li diu a l’equip d’IA que no utilitzi el text de les activitats extracurriculars.
Aspectes per garantir una IA ètica
És possible que tant els sistemes d’IA com els humans estiguin esbiaixats, però resulta més fàcil d’identificar i corregir-los en el cas de la tecnologia. Aquests són els quatre passos que pots seguir en construir els teus sistemes d’IA:
– No confiïs en els models de caixa negra. Insisteix en què la IA proporcioni explicacions amigables amb l’ésser humà.
– Comprova si el model discrimina directament, observant l’impacte i els efectes de les característiques, així com els núvols de paraules.
– Verifica si el model esbiaixa indirectament, construint models que pronostiquin el contingut de característiques sensibles (per exemple, el gènere).
– Utilitza dades d’entrenament que representin el comportament desitjable per a l’aprenentatge de la IA. Supervisa activament les dades i resultats, i alerta quan les noves dades siguin diferents de les dades educatives.
Tal com apunta Meredith Broussard, autora del llibre ‘Artificial Unintelligence: Com els ordinadors malinterpreten el món‘, “quan només utilitzem sistemes computacionals i assumim que faran millor la feina que els humans, estem sent tecnochovinistes (la creença que la solució tecnològica és sempre la correcta). Necessitem anar més enllà d’això i tenir un enfocament més matisat, emprant la IA per evitar replicar el món tal com és, sinó com hauria de ser”.
En definitiva, la IA no és ni bona ni dolenta, dependrà de com l’entrenem.
Article editat i publicat originalment a DataRobot
Nae és partner certificat de DataRobot per a solucions de machine learning automatitzat i intel·ligència artificial orientades a l’empresa, i especialista en automatitzar el flux de treball de la ciència de dades, tant per a la recomanació d’algoritmes com per a la construcció de models predictius.

