Artículo
Cuatro claves para evitar los prejuicios en la IA


La IA no es ni buena ni mala, dependerá de cómo la entrenemos
Recientemente salió la noticia de que la inteligencia artificial de Amazon, tecnología que utilizó desde el año 2014 hasta principios de 2017 para seleccionar currículums, discriminaba a las mujeres. Esta no es la primera vez que se informa de este tipo de problema, y no será la última, ya que los sistemas sesgados son una trampa común en la que las empresas pueden caer fácilmente.
En el caso del gigante del comercio electrónico, que ha dejado de utilizar esta tecnología en sus procesos de selección de personal, el problema radicó en que la IA había sido entrenada con currículums de hace 10 años, con una fuerte presencia masculina. De este modo, la IA tenía un sesgo en favor de los hombres y penalizaba los currículums de mujeres, aunque la variable “sexo” se eliminara del modelo.
El problema que tuvieron fue que ser mujer u hombre estaba muy correlacionado con otra información implícita en los currículums (escuela, aficiones, el propio nombre, etc.). Para eliminar el sesgo no bastaba con eliminar la palabra “mujer/hombre”, sino que era necesario descubrir y eliminar toda la información relacionada.
¿Qué es un sesgo?
No existe una definición generalmente aceptada de sesgo, salvo que es lo contrario de la justicia. Un video tutorial publicado en YouTube a principios de este año enumera 21 definiciones diferentes de justicia en un algoritmo. Si bien no existe una definición estándar, hay un par de pensamientos clave al respecto:
Discriminación injusta e ilegal: Tratar a las personas de manera diferente
Hay muchos tipos de discriminación ilegal, siendo las más conocidas el género y la raza. Sin embargo, hay científicos de datos que construyen modelos que utilizan estas características para entrenar sistemas de IA que posteriormente serán utilizados para tomar decisiones.
Una manera sutil de que la discriminación se introduzca en un modelo es utilizar características que están fuertemente relacionadas con atributos discriminatorios. Por ejemplo, en Estados Unidos la raza de una persona está estrechamente ligada con su domicilio. Es por eso que a los bancos estadounidenses no se les permite usar códigos postales al tomar decisiones sobre préstamos.
Es importante tener en consideración las características que no son éticas, que podrían causar riesgo de reputación o aprovecharse de colectivos vulnerables. Por ejemplo, existen modelos económicos que predicen que los clientes de edad avanzada tienen una sensibilidad de precios más baja (tal vez porque no tienen la capacidad de acceder a Internet para hacer una comparativa de precios), por lo que se les termina cobrando importes considerablemente más altos. En esa situación, no es ilegal cobrarles más, pero muchos considerarían poco ético aprovecharse de una persona vulnerable.
Consolidación de la desventaja histórica
Una IA sólo sabe lo que se le enseña. Es como enviar a un niño a la escuela, aprende con el ejemplo de los datos históricos. Si entrenas a un sistema de IA con datos sesgados, entonces aprenderá a tomar decisiones sesgadas. Los científicos de datos, responsables de construir y formar estos sistemas, tienen habilidades similares a las de los profesores. Del mismo modo que no usamos libros de texto de hace cien años, no deberíamos entrenar IAs con datos que contienen resultados tendenciosos. Si los datos históricos contienen ejemplos de malos resultados para los grupos desfavorecidos, entonces esta tecnología aprenderá a reproducir las decisiones que conducen a esos malos resultados.
Cuando una IA aprende a repetir los errores humanos, afianza ese comportamiento para el futuro. Por ejemplo, si un sistema de IA se forma con datos recopilados durante un período durante el cual las mujeres tenían menos probabilidades de tener éxito al solicitar un empleo (posiblemente debido a prejuicios o a roles tradicionales de género), entonces el sistema aprenderá a dar prioridad al colectivo masculino.
Caso de estudio – Cómo evitar los prejuicios en los sistemas de IA
Una empresa, llamémosla Techcorp, quiere construir un algoritmo para clasificar las grandes cantidades de solicitudes que recibe cada vez que publica un anuncio de trabajo, por lo que ha decidido entrenar un algoritmo de machine learning con los resultados de su campaña de contratación anterior (con variables como la edad, el género, la educación y otros detalles sobre el perfil de cada solicitante).
Entrena el algoritmo sobre sus datos históricos y está muy satisfecha de poder predecir qué candidato obtendrá el trabajo con una tasa de precisión alta. Esto debería ahorrar a su equipo de recursos humanos la mitad del tiempo que pasan leyendo currículums.
Pero ese no es el final del proyecto. Elle Smith, la nueva Directora de Recursos Humanos de Techcorp, no confía en la caja negra. Se pregunta qué factores está utilizando la IA para tomar sus decisiones. El informe que recibe del equipo de IA le muestra una representación de la importancia que se le da a cada nuevo dato a la hora de tomar decisiones.


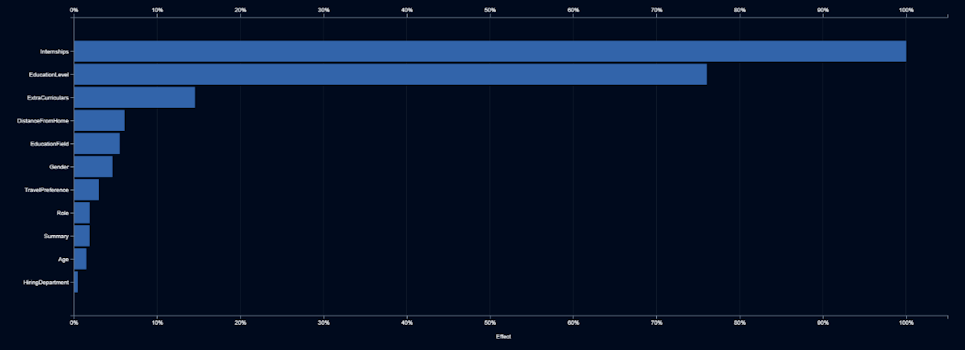
El anterior informe le muestra que el género es el sexto input más importante. Así que Elle Smith se pregunta qué está sucediendo con el género. La información que recibe le muestra lo que hace la IA, con diferentes valores, para una característica de entrada:


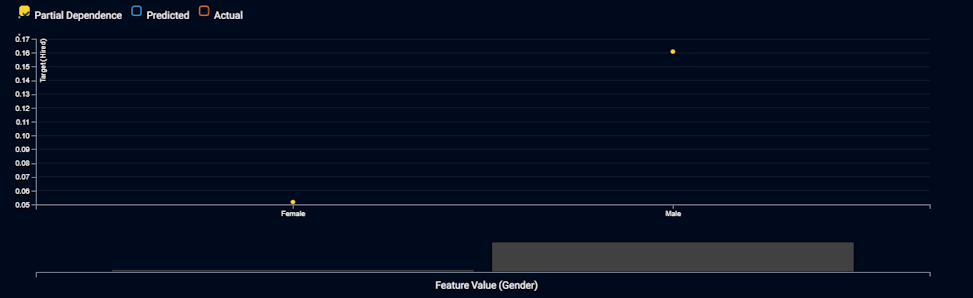
El gráfico muestra que la IA elegirá 3 veces más a menudo a los hombres que a las mujeres, siendo las demás variables igualitarias. Elle declara que esto es discriminación directa y que es ilegal, y exige que el equipo de IA elimine el género del modelo. Así que construyen una nueva IA que no utiliza el género como variable.
El equipo de IA presenta su modelo de segunda generación y declara que es tan preciso como el primero, a pesar de haber abandonado el campo del género. Pero Elle sigue sospechando, por lo que pide ver qué variables de entrada son las más importantes.

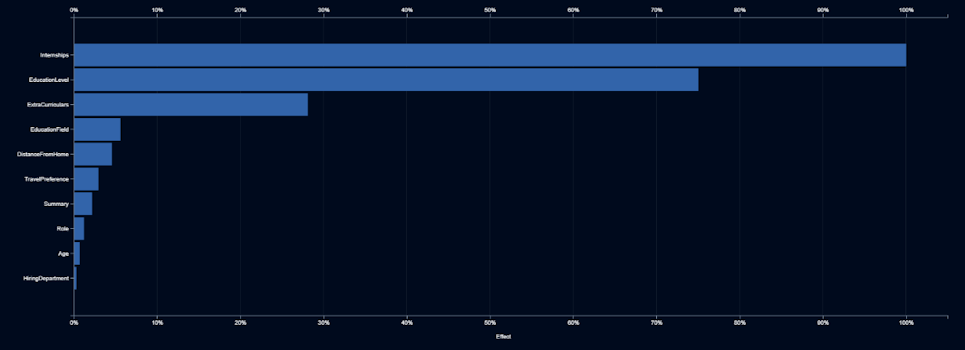
Elle detecta que los períodos de prácticas, la educación y las actividades extracurriculares son los indicadores más fuertes. Aunque todo esto tiene sentido, una vez más, pregunta qué está haciendo la IA con estas características. Las becas y la educación tienen sentido, ya que los más formados y con más experiencia tienen más probabilidades de ser contratados. Decide buscar en una nube de palabras la descripción de actividades extracurriculares.



Descubre que los candidatos son más propensos a ser contratados si practicaron fútbol, un deporte dominado por hombres; y menos propensos a ser contratados si jugaron a balonmano o softball, deportes dominados por mujeres. Además, si el candidato forma parte de un equipo deportivo femenino de cualquier tipo, ¡tiene aún menos probabilidades de ser contratado! El texto que describe las actividades extracurriculares resulta ser, en sí, un indicador de género, así que utilizarlo no se diferencia en nada a usar el género.
Elle pide al equipo de IA que identifique cualquier otra característica que pueda ser un indicador de género. Lo hacen construyendo modelos que predicen la probabilidad de que un candidato sea una mujer, basándose en cualquiera de las otras características.

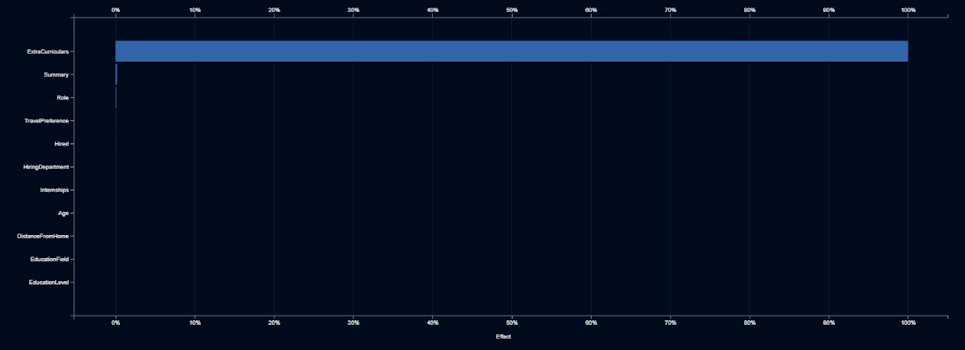
El gráfico muestra que la actividad extracurricular es el único indicador significativo de género, por lo que Elle le dice al equipo de IA que no use el texto de las actividades extracurriculares.
Aspectos para garantizar una IA ética
Es posible que tanto los sistemas de IA como los humanos estén sesgados, pero resulta más fácil de identificar y corregir en el caso de la tecnología. Estos son los cuatro pasos que puedes seguir al construir tus sistemas de IA:
– No confíes en los modelos de caja negra. Insiste en que la IA proporcione explicaciones amigables con el ser humano.
– Comprueba si el modelo discrimina directamente, observando el impacto y los efectos de las características, así como las nubes de palabras.
– Verifica si el modelo sesga indirectamente, construyendo modelos que pronostiquen el contenido de características sensibles (por ejemplo, el género).
– Utiliza datos de entrenamiento que representen el comportamiento deseable para el aprendizaje de la IA. Supervisa activamente los datos y resultados, y alerta cuando los nuevos datos sean diferentes de los datos educativos.
Tal y como apunta Meredith Broussard, autora del libro ‘Artificial Unintelligence: Cómo los ordenadores malinterpretan el mundo’, “cuando sólo usamos sistemas computacionales y asumimos que van a hacer un mejor trabajo que los humanos, estamos siendo tecnochovinistas (la creencia de que la solución tecnológica es siempre la correcta). Necesitamos ir más allá de eso y tener un enfoque más matizado, usando la IA para evitar replicar el mundo tal y como es, sino como debería ser”.
En definitiva, la IA no es ni buena ni mala, dependerá de cómo la entrenemos.
Artículo editado y publicado originalmente en DataRobot
Nae es partner certificado de DataRobot para soluciones de machine learning automatizado e inteligencia artificial orientadas a la empresa, y especialista en automatizar el flujo de trabajo de la ciencia de datos, tanto para la recomendación de algoritmos como para la construcción de modelos predictivos.

