Article
Algoritmes i desigualtat, poden les màquines tenir prejudicis?


Cal ser més curós amb qui es tria per dissenyar i entrenar els sistemes d’aprenentatge automàtic, ja que la intel·ligència artificial reflectirà els valors dels seus creadors.
Quan naveguem per les nostres xarxes socials preferides, quan estem decidint que veure a Netflix un diumenge a la tarda o quan busquem qualsevol cosa a Google, ens estem deixant guiar per un algoritme, un conjunt de regles que determina, entre altres possibles paràmetres, quin contingut ens pot interessar més i quina informació s’adequa amb més precisió al nostre estil de vida i als nostres gustos
Perquè els resultats que se’ns mostrin concordin al màxim amb els nostres interessos, als algoritmes se’ls nodreix amb enormes quantitats d’informació, a partir de les quals estableixen nodes de relació i troben patrons. Freqüentment, les dades amb les quals s’ha alimentat a l’algoritme són escollides prèviament per humans. El problema radica en què a vegades l’elecció de quina informació incorporar i quines dades obviar pot ser tendenciosa pel que fa a raça o gènere. “Els algoritmes són versions automatitzades i simplificades de qualsevol procés humà burocràtic que hagin reemplaçat. Estan entrenats amb les dades històriques que va produir aquest procés”, explica Cathy O’Neill, matemàtica i autora d’Armes de destrucció matemàtica (Capitán Swing, 2016), “això significa que, si el procés estava esbiaixat sistemàticament a favor de cert grup, l’algoritme resultant normalment també ho estarà”.
“Això és fonamentalment un problema de dades. Els algoritmes aprenen sent alimentats amb certes imatges, sovint escollides per enginyers, i el sistema construeix un model del món basat en aquestes imatges. A un sistema entrenat amb fotografies de persones que són, en la seva majoria, blanques, li serà més difícil reconèixer cares no-blanques”, exposa Kate Crawford, especialista en les implicacions socials de la intel·ligència artificial. Aquesta afirmació es pot comprovar amb un exemple senzill: sol·licitem a qualsevol buscador imatges de “bebè” o “baby” i tindrem infinits resultats, majoritàriament de bebès blancs i occidentals.
Un professor de la Universitat de Virgínia va observar un patró en algunes conjectures fetes pel software de reconeixement d’imatges que estava creant, “veia una fotografia d’una cuina i amb freqüència l’associava amb dones més que amb homes”. A partir d’aquesta advertència, es va preguntar si havia estat nodrint l’algoritme amb informació esbiaixada, pel que es va analitzar els etiquetatges de les imatges que havia utilitzat: efectivament, els bancs de fotografies amb els que treballava mostraven una discriminació predicible en la representació que deien de certes activitats. Mentre que imatges de compres o de neteja estaven relacionades amb dones, accions com entrenar o disparar estaven vinculades amb homes. El problema es va agreujar quan l’equip es va adonar que el programa d’aprenentatge automàtic que havia entrenat no només reflectia aquests biaixos, sinó que els amplificava, enfortint aquestes associacions.
El biaix en què l’aprenentatge dels softwares i, en conseqüència, els resultats que es mostren als usuaris, no passa només amb les imatges. Quan una intel·ligència artificial assimila un idioma nou, aprèn també la discriminació present en el mateix llenguatge, pel que acaba apropiant-se (i reproduint) alguns estereotips, segons un estudi de la Universitat de Princeton. El treball d’ Aylin Caliskan, autora principal de la investigació, parteix de la idea que algunes característiques del significat de les paraules
pot deure’s a la manera en què aquestes estan ordenades, al context sobre el qual estan disposades. Els investigadors van desenvolupar un software nodrit amb 2 milions de paraules, per veure com realitzava associacions. Els resultats van ser similars als de la Universitat de Virgínia: la màquina relacionava noms femenins amb tasques de la llar i noms masculins amb paraules vinculades a la carrera professional.
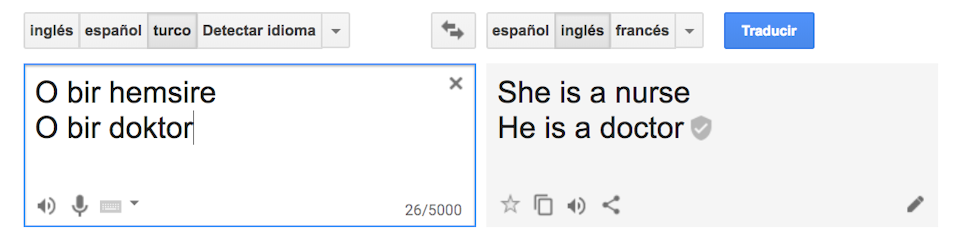
Un cas analitzat dins d’aquest estudi va ser la traducció automàtica, posant com a exemple la traducció del turc a l’anglès amb el servei de traducció de Google. Tot i que el turc té pronoms neutres, el traductor va interpretar les frases amb pronoms estereotipats:


Altres exemples sonats d’algoritmes que van mostrar resultats esbiaixats van ser el chatbot de Microsoft, el concurs de bellesa amb una intel·ligència artificial com a jutge i la discriminació als anuncis d’ocupació a Google. En el primer cas, la companyia tecnològica va crear un compte de Twitter gestionat per un software d’IA anomenat Tay, que estava dissenyat perquè anés aprenent a través de les interaccions que els usuaris tinguessin amb ell. Tot i que l’experiment va començar bé, Tay va passar ràpidament a divulgar missatges racistes i completament inapropiats. Microsoft va tancar el compte i es va disculpar pels resultats.
L’any 2016, va tenir lloc el primer concurs de bellesa jutjat per intel·ligència artificial. El programa prometia jutjar aspectes imparcials com la simetria del rostre o les arrugues, però dels 44 guanyadors, la majoria eren blancs, alguns asiàtics i tan sols una persona de pell fosca. Davant l’aparent objectivitat de la selecció, els resultats reflectien una clara preferència cap a la pell clara. El problema principal, segons el responsable científic del concurs, va ser que les imatges que el projecte va utilitzar per establir els estàndards de bellesa no incloïen suficients dades de minories.
La Universitat Carnegie Mellon va revelar fa tres anys que es mostraven anuncis d’ocupació de retribució elevada a bastants més homes que dones. Segons l’estudi que es va dur a terme, l’anunci d’un lloc de treball amb un sou de més de 200.000 dòlars es va mostrar 1.800 vegades a usuaris masculins, mentre que només es va ensenyar 300 vegades a usuaris femenins. Un dels possibles efectes d’aquest tipus de discriminació basada en el gènere és la desigualtat en els llocs de treball: les dones no poden aplicar a posicions que no se’ls ofereixen.
Tots els algoritmes són tan bons com les dades que posem en ells. “Cap sistema d’intel·ligència artificial té intencionalitat, però les decisions que aprèn estan basades en les dades amb les quals ha sigut entrenat”, afirma el director de l’Institut d’Investigació en IA del CSIC. Tot i que els exemples que s’han utilitzat en aquests articles són importants, hi ha decisions que prenen intel·ligències artificials que poden tenir conseqüències encara més greus: hi ha algoritmes que decideixen qui té dret a una hipoteca, a una pòlissa de vida o a un préstec universitari.
Què es pot fer per aconseguir que els algoritmes no perpetuïn els biaixos humans? La inclusivitat és un dels eixos pels quals molts investigadors aposten: s’ha de ser més curós amb qui s’escull per dissenyar i entrenar els sistemes d’aprenentatge automàtic, ja que la intel·ligència artificial reflectirà els valors dels seus creadors. Formar equips on s’incloguin dones i minories ètniques podria ser un dels passos cap a una menor discriminació.
Alguns especialistes aconsellen, a més a més, que tots els involucrats en aquest tipus de tecnologies tinguin algun tipus de formació en valors, perquè siguin conscients de la importància de les seves accions. Finalment, altres experts assenyalen que la responsabilitat és també de tots els que bolquem continguts a la xarxa, doncs les màquines aprenen de les dades i les interaccions dels usuaris. En aquesta línia coincideix Caliskan, que afirma que, si s’utilitzés un llenguatge més inclusiu, les associacions estereotípiques disminuirien.
Els algoritmes seran com nosaltres vulguem que siguin i no ens podem permetre que aquelles màquines que prenen decisions per nosaltres, que ens acompanyen en el dia a dia i a les que atorguem un cert grau d’objectivitat reprodueixin i amplifiquin els errors humans.

